
Dropout is a training method for addressing overfitting in a deep learning model, and has been disclosed through papers such as Improving neural networks by preventing co-adaptation of feature detectors (2012), and Dropout: a simple way to prevent neural networks from overfitting (2014).
Then what exactly is dropout? During the dropout training process, a certain ratio of nodes in each mini batch are randomly selected and are disabled, and this process is repeated. In each mini batch, data is trained with models that have different net structures, and these models have a similar effect as an ensemble. This thus solves the overfitting problem and also prevents co-adaptation by certain nodes.

[Source: "Dropout: A Simple Way to Prevent Neural Networks from overfitting, Hinton et al."]
Surprisingly, Google is still continuing its process of patenting the dropout technology. To be clear, although Google got granted dropout patents three times after making its first attempt in December 2012, it is ongoing a new process to get the optimal patent registered.
The US patent process: provisional application
First, let’s look at the history of Google’s dropout patents filed in the USPTO.

[Source: keywert.com]
After its initial filing of a dropout patent in the name of “System and method for addressing overfitting in a neural network” on December 24, 2012, Google continued filing dropout patents in 2013, 2016, 2019, and 2021.
The patent registered on December 24 2012 has gone through a process called provisional application in the US patent system.
Most countries including the US determine the priority of an invention based on the date of submission to the patent office.
But since a patent specification should follow a certain format, it requires quite a time to work on a patent specification. This is why a provisional application is for, to help inventors submit their inventions to the patent office as soon as possible free from the restrictions of formats and requirements. Through the provisional application process, an applicant can submit materials such as papers or presentation materials in advance and secure the priority of the invention.
In fact, Google’s provisional application submitted on December 24, 2012 is very much similar to the contents of Improving neural networks by preventing co-adaptation of feature detectors (2012).
A provisional application does not become the target of examination, and when a regular application is submitted to the patent office after completing the specification, the common contents are examined based on the date of the provisional application.
The four patents filed after 2012 (2013:US9,406,011, 2016: US10,366,329, 2019: 10,977,557, and 2021:17,227,010) are all regular applications which have the correct format of a specification and are the target of examination.
So far, the four patents have been proceeding as follows.
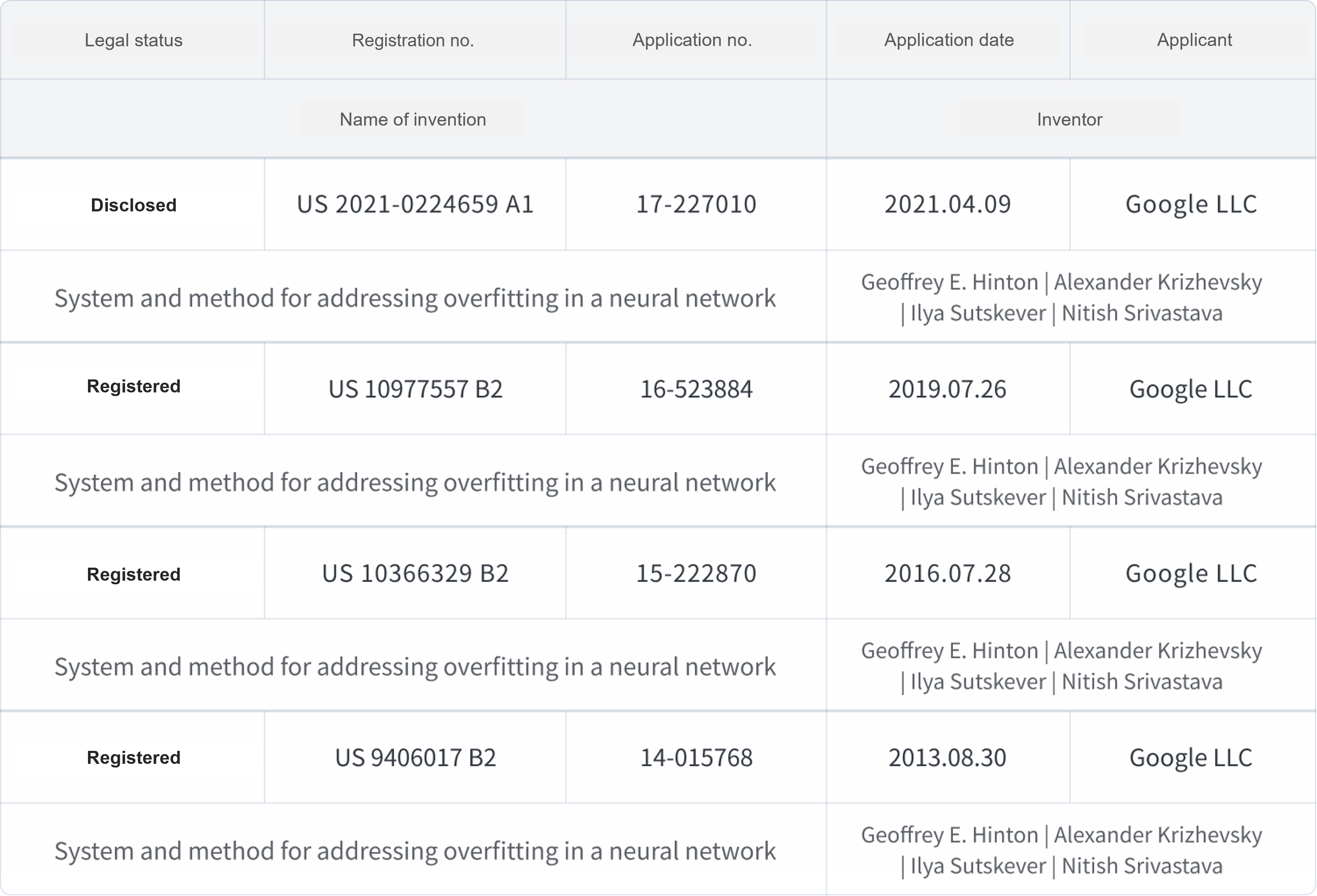
The three patents filed in 2013, 2016, and 2019 have been registered after the USPTO’s examination. The latest one filed on April 9, 2021 is currently going through examination.
Then, what is the reason for Google’s filing four patents for one dropout technology? And what relation do the four patents have to each other?
Patent registration process of 2013: We got it granted, but we want some more.
In order to figure out why Google filed four patents for a single dropout technology, we should look into the patent registration process of the first patent. Basically, the four patents share the patent specification with the same technology.
Figuring out a patent registration process is in other words, figuring out how the scope of patent claims changes. Patents are about applying an exclusive right to one’s technology, and the scope of the exclusive rights are determined by the patent claims in the patent specification.
After all, a patent registration process is like playing tug-of-war between the applicant and the examiner.
To begin with, let’s take a look at the regular application (US14/015,768) initially filed in 2013.

The claims on the left side are the claims which Google attempted to register in the first place, and the claims on the right side are the claims that were actually registered in the end.
In order for infringement of a patent to be acknowledged, the patent holder should prove that the other side (the possible infringing party) is using all components of the registered patent claims. Therefore, each and every component included in patent claims become factors that minimize the scope of the patent. The opponent side can avoid their charges of patent infringement just by not using one single component of the patent claims. Contents of patent claims can be a factor that limits patentees’ rights, and also work as an excuse for the opponent side to avoid the accusation of patent infringement.
As such, the contents that have been added to the initial claims give us a clue on which parts of the patent rights the patentee has given up.
The initial claims of 2013 defines 1) obtaining training cases and 2) training neural network with the data as the main phase, and 2) describes the detailed dropout training method in the sub phases of training.
Dropout training method of the initial claims of 2013 discloses 1) determining which feature detector to disable, 2) disabling nodes depending on the determination, and 3) training with the training cases obtained through disabled state.
The parts that have been added to the initial claims is “a subset of the feature detectors being associated with respective probabilities of being disabled during processing of each of the training cases, determining whether to disable each of the feature detectors in the subset based on the respective probability associated with the feature detector”.
This is the part that has been added by the patentee during the examination process, and has been given up for patent registration. As explained above, components that have been added to a patent claim limits the patentee’s rights.
Even after the patent has been granted, Google can claim patent infringement only when all parts of the claims including “the probability of part of the nodes being disabled is set, and whether each node is disabled is affected based on this probability” has been used by a third party.
Of course, when we look at the source code of dropout provided by Tensorflow, it includes the structure of setting a probability which leads to disabling each node and determining the percentage of nodes to be disabled based on this probability (Please refer to our column, Digging Deeper into TensorFlow. Insights on Google’s AI Patents)
.png) [Source: Chung Hwe Hee, researcher at SUALAB]
[Source: Chung Hwe Hee, researcher at SUALAB]
But just because the technology used by oneself has been registered as is, it doesn’t mean that it is not problematic. Of course, freely determining the nodes’ dropout probability in the library and probabilistically controlling the nodes of a neural network may be 100% utilizing the dropout function.
Then, if a third party gives up probabilistically controlling the nodes in the dropout training method, does this mean they cannot fully utilize the effects of the dropout training method? What would happen if each mini batch that will be trained with each node in the state in which the structure of a certain neural network is set is deterministically disabled?
One of the principles of dropout to prevent overfitting, is that since the disabled nodes in each mini batch differ in a neural network, it has the effect as if neural networks with different structures are being trained in each mini batch unit. In the time point when inference occurs in a neural network that has been finally trained, a plurality of neural networks that are disabled with different nodes make an effect like ensemble and therefore solve the overfitting problem.
This structure would not change even if the condition of nodes being disabled is controlled not by probability but deterministically. Of course, when each node is deterministically controlled, the dropout function (“deterministic dropout”) itself may have less versatility to apply to random neural networks, or may not be able to take advantage of the randomization of the nodes that are disabled in a neural network. Even so, we cannot say that deterministic dropout itself does not take the advantages of the core mechanisms of general dropout at all.
In other words, we can suppose that if a general dropout can take advantage of effects in 100, a deterministic dropout would get 70, 50, or 30.
A patent right is effective when there’s competition. One can have a competitive advantage over a competitor through patent rights by preventing them from using the technology one developed for a certain period of time. But what would happen if a competitor takes not necessarily 100% of my technology but part of the technology and develops a product that has 70% effect of the original with 50% less price?
If this happens, the patentee has to fight with the third party who is using part of their technology, and also compete on price. This will prevent the patentee from having an exclusive right and also full market power.
Google might have not been satisfied with the scope of rights of the patent that was granted in 2013. But there’s no in between in terms of patent registration. You either accept the scope of patent rights and get it granted, or give up patent registration.
Further, once a patent is registered, it is virtually impossible to change the confirmed scope of rights later on.
What could Google do in this situation?
Continuation application: Please give us another chance!
In this circumstance one of the options the patentee can choose is to first register the granted patent and seek for securing a wider scope of rights by branching out with new patents. The system varies by country, but according to the US Patent Law this is supported through continuation application, and also divisional application, continuation in-part application is available. So far, to secure a wider scope of patent rights they first intended to have, Google has continued their application in 2016, 2019, and 2021 through the continuation application system.
After getting the patent granted in 2013 (and accepting the USPTO’s decision for then), the patent claims that were filed in 2016 are as follows. (To help your understanding, the contents that are similar to the 2013 version are highlighted in the same color.)

Compared with the 2013 version, the first characteristic of the 2016 version is that 1) in order to describe different nodes being disabled in a plurality of mini patches, it described different nodes being disabled depending on the first training case and the second training case. (processing the second training case with at least one of the feature detectors in the first set of feature detectors enabled and the second, different set of feature detectors disabled to generate a predicted output for the second training case).
The second characteristic is that 2) due to such characteristic of dropout, it is directly mentioned in the patent claims that “thereby reducing overfitting and reducing co-adaptation of feature detectors by reducing reliance on the first set of one or more feature detectors by other feature detectors in the neural network”.
There’s a technical method used when writing patent claims. When “N” number of entities have different characteristics to each other or are each performing different motions, it is to describe that among “N” entities there is the first entity and second entity which each have different characteristics to each other or are performing different movements.
In this case, the claims can cover the case in which the “N” entities all have different characteristics or are performing different movements. And even if some of the entities have identical characteristics or are performing the same movement, this could be covered as well.
The patent registered in 2016 also uses this method and describes “different nodes being diabled in each mini batch during the dropout process” as “there exists random first training case and second training case, and in the two training cases different nodes are being disabled”.
What is noteworthy in the 2016 version is that the patent claims include the effects of the dropout training method which is the reduction of co-adaptation and overfitting.
Generally, it is not desirable to include the effects of a certain technology in the patent claims. During examination, it is the components not the effects of the technology that is considered important. Thus, including the effects of a technology isn’t so helpful for registration, but may rather limit the scope of patent rights later on.
Google got granted the patent with this content in 2016, and maybe because they didn’t like the part that describes the effects of the invention, they continued filing again in 2019.

In the continuation application filed in 2019, Google succeeds in deleting the content “thereby reducing overfitting and reducing co-adaptation of feature detectors by reducing reliance on the first set of one or more feature detectors by other feature detectors in the neural network”.
But instead, the composition that describes the training process by repeating the first mini batch (training case) and the second mini batch has been maintained as same as the 2016 version, and “enabling the first set of one or more feature detectors after processing the first training case using the neural network and prior to processing a second training case of the plurality of training cases using the neural network” has been added.
By all appearances the content doesn’t seem to have major problems, but Google made a new continuation application in 2021 again, and the claims are currently under examination.

As the 2021 version has not been granted yet, the current claims are the initial version that has been submitted. The initial claims of the 2021 version are almost identical to the components of the claims of regular application in 2013.
It is highly likely that the patent claims would not be granted without amendments. This is even more likely because if the continuation application of 2021 is granted as is, the USPTO will be denying their own decision they made in 2013.
The reason behind repeated continuation application: a portfolio strategy for a single technology
Then why is Google never satisfied and is repeating the continuation application process?
Although I cannot 100 percent affirm what Google is thinking about, I could predict that they may be implementing a strategy to secure a patent portfolio of an important single technology.
For example, I would like to illustrate below the initial scope of patent rights that were described by the initial claims in the patent registration process in 2013 and the scope of rights that were actually granted in the registered claims.

As you can see from the picture, the scope of rights that were actually granted was only a part of the scope of rights that Google initially attempted. In this case, Google cannot prevent competitors from penetrating into the gap between the initial scope of rights and the granted scope of rights.
But through Google’s repeated attempts of continuation application, they secured their patents in 2016 and 2019, and were able to establish various patents that have diverse aspects of scope of protection in terms of dropout patents. Through this process, Google was able to bridge the gap between the initial scope of rights and the secured scope of rights.

The patent registered in 2021 also may not cover the entire scope of rights that was initially intended, but by securing patents that can bridge other gaps it can additionally obtain a range of patent protection that is more committed to dropout patents.

As competition becomes fierce and products and technologies are fragmentized, there is only a bare chance for a product to be protected by a single patent.
By taking advantage of various systems such as provisional application and continuation application which we have introduced above, patentees can practically protect important products or technologies, and many foreign companies (especially US companies) are already actively utilizing such strategies.
Similar system in Korean Patent Act: provisional application and divisional application
Such similar systems also exist in the Korean Patent Act. The provisional application system which was made on the model of the US provisional application system was introduced to help applicants secure the fastest application date not being subject to formality.
Although it isn’t specified as the American system of continuation application, continuation in-part application, and divisional application, the divisional application system of the Korean Patent Act also lets applicants file a new application for a patent application that shares the same content.
Thanks to amendments to the Act, it is also possible to file after getting a patent granted according to the Korean divisional application system, which can be used similarly to the continuation application system.
However, unlike foreign firms, most Korean companies are still not familiar with using the US continuation application or the Korean divisional application system. According to PI IP LAW’s internal statistics, it turned out that Samsung Electronics’ rate of utilizing the continuation application system was remarkably low compared to major US patent filers such as Microsoft, Oracle, and IBM.

In order to establish an effective patent strategy, not only quantitative investment to obtain patents above a certain level, but also a strategy to effectively utilize the system is necessary. I strongly hope Korean patent filers would also take this into consideration and focus on strategic use of the patent application system.
