
안녕하세요, 이대호 변리사입니다.
Dropout은 딥러닝 모델의 과적합(overfitting)을 해결하기 위한 학습방법으로 2012년 Improving neural networks by preventing co-adaptation of feature detectors 2014년 Dropout: a simple way to prevent neural networks from overfitting 등의 논문등을 통해 세상에 공개되었습니다.
널리 알려진 Dropout의 개념은 트레이닝 과정에서 각각의 미니 배치(mini batch)마다 일정 비율의 노드를 랜덤하게 선택해 트레이닝 과정에서 디스에이블(disable)하고 이를 반복하는 방식입니다. 각 미니 배치마다 마치 서로 상이한 망구조를 가진 모델에 데이터들이 학습되고, 마치 이러한 모델들이 앙상블(ensemble)된 것과 같은 효과를 가지게 되면서 과적합(overfitting) 문제를 해소하고, 특정 노드들에 의한 동조화(co-adaptation)을 방지하는 효과를 가지고 있습니다.
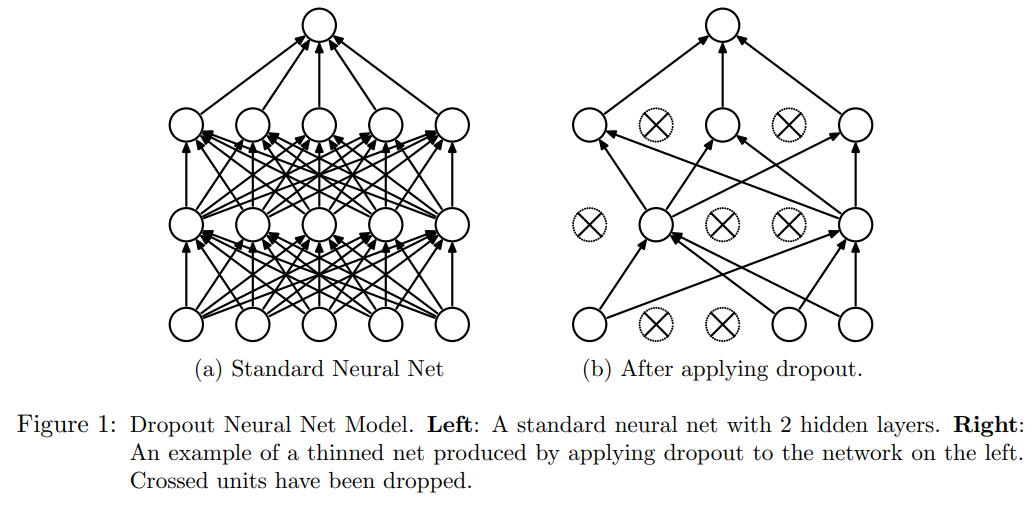
출처는: Dropout: A Simple Way to Prevent Neural Networks from overfitting, Hinton et al.
이러한 Dropout 기술에 대한 특허가 아직도 등록을 위한 절차를 진행하고 있는 중이라고 하면 믿으시겠습니까? 정확히 말하면 구글이 2012년 12월에 특허등록을 위한 시도를 1차로 진행한 이후, 3번에 걸쳐 등록을 받았으나, 아직도 맘에 드는 특허를 받기 위해 새로운 절차를 진행하고 있는 중입니다.
미국출원 절차: 가출원(Provisional Application)
먼저, 구글이 dropout 과 관련해서 미국 특허청에 출원한 특허출원 들의 히스토리를 살펴보도록 하겠습니다.

출처는 keywert.com
구글은 dropout 과 관련한 특허를 “System and method for addressing overfitting in a neural network”이라는 이름으로 2012년 12월 24일에 최초로 출원한 후, 2013년, 2016년, 2019년 및 2021년에 반복하여 출원했습니다.
2012년 12월 24일에 출원된 특허출원은 미국 특허제도상 가출원(provisional application)이라는 절차를 통해 출원되었습니다.
미국을 포함한 대부분의 나라들은 누가 어떤 발명을 먼저 하였는지에 대한 우선순위를 특허청에 제출한 날짜를 기초로 판단합니다.
그러나 특허 등록을 신청하기 위한 특허 명세서는 일정한 양식을 갖춰야 하고, 발명을 제대로 보호하기 위해서 명세서를 작업하는데 일정한 시간이 소요됩니다. 가출원제도는 이러한 제약 하에서, 발명자가 형식에 구애받지 않고 하루라도 빨리 자신의 발명 내용을 특허청에 제출할 수 있게 하기 위한 제도 입니다. 특허출원인은 명세서의 형식적 요건을 갖출 필요 없이, 자신이 발표한 논문이나, 발표자료와 같은 자료를 먼저 제출하고, 자신이 해당 내용을 발명했다는 우선권을 확보할 수 있습니다.
실제로 2012년 12월 24일에 제출된 구글의 가출원은, 2012년 Improving neural networks by preventing co-adaptation of feature detectors 논문의 내용과 많은 부분이 유사합니다.
가출원은 실제로 심사의 대상이 되지 않고, 나중에 충분한 시간을 거쳐 작성된 본 출원의 명세서가 특허청에 제출되면, 공통 기재 부분에 대해서는 해당 가출원이 제출된 날짜를 기준으로 본출원을 심사하게 됩니다.
2012년 이후로 출원된 4개의 출원(2013년:US9,406,011, 2016년: US10,366,329, 2019년: 10,977,557 및 2021년:17,227,010)은 모두 특허청이 요청하는 특허 명세서의 양식을 갖추고, 실질적인 심사의 대상이 되는 본출원에 해당합니다.
현재 4개 특허의 진행상황은 다음과 같습니다.

2013년, 2016년 그리고 2019년 출원된 3개의 특허는 미국특허청의 심사를 마치고 등록된 상태입니다. 그리고 새로 2021년 4월 9일에 출원된 출원은 아직 미국 특허청에서 심사절차를 밟고 있습니다.
그렇다면 dropout 하나의 기술에 대해서 4개의 특허가 신청된 이유는 뭘까요? 각각의 4개의 특허는 서로 어떤 관계를 가지고 있을까요?
2013년 특허의 등록과정: 등록은 받았으나 썩 맘에는 안들어...
구글이 dropout 기술 하나에 대해서 4개의 특허를 내게 된 이유를 파악하기 위해서는 최초의 특허의 등록과정을 살펴보아야 합니다. 기본적으로 4개의 특허는 모두 동일한 기술 내용이 기재된 특허명세서를 공유하고 있습니다.
특허가 등록되는 과정을 살펴보는 과정은 곧, 특허의 청구항(Claim)에 따라 특허의 청구범위가 어떻게 변화되었는지를 파악하는 것과 동일합니다. 특허는 결국 자신의 기술에 대한 독점권을 신청하는 것입니다. 그리고 그 독점권이 어디까지 효력이 미치는지(특허청구범위)는, 특허 출원서에 기재된 특허 청구항에 의해 결정됩니다.
특허의 심사 과정이라 함은 결국 특허청구항을 수정하면서 특허출원인과 심사관이 서로 줄다리기를 하는 과정입니다.
일단 2013년 최초로 출원된 본출원(US14/015,768)을 살펴보겠습니다.

왼쪽에 보이는 청구항이 구글이 최초로 등록하고자 했던 청구항이고, 오른쪽이 최종적으로 등록된 청구항입니다.
특허 침해가 성립하기 위해서는 등록된 특허 청구항의 모든 구성요소를 상대방이 사용하고 있음을 입증해야 합니다. 따라서 특허 청구항에 포함된 구성요소들 하나하나가 최종적인 특허청구범위를 축소시키는 요소가 됩니다. 특허권자가 아닌 상대방에게는 특허청구항에 포함된 구성요소 중 하나라도 사용하지 않으면 특허 침해주장을 피해갈 수 있습니다. 특허 청구항에 적힌 내용이 특허권자에겐 자신의 권리를 제한하는 요소이자, 상대방에게는 특허 침해 주장을 피해갈 수 있는 빌미가 되는 것입니다.
따라서 최초 청구항과 등록된 청구항에서 추가된 부분은 특허권자가 자신의 기술에 대한 특허권의 권리범위 중 어느 부분을 포기했는지를 알 수 있는 단서가 됩니다.
2013년 특허의 최초 청구항을 살펴보면, 1) 트레이닝 데이터(training case)를 확보하고, 2) 해당 데이터로 뉴럴네트워크를 훈련시키는 구성을 메인 단계로 정의하고 있으며, 2) 훈련 시키는 구성의 서브 단계들에서 구체적인 dropout 학습 방법을 서술하고 있습니다.
2013년 최초 청구항에서 dropout 학습방법은 1) 어떤 노드(feature detector)를 디스에이블링(disabling)할지를 결정하고, 2) 해당 결정에 따라 노드들을 디스에이블링하며, 3) 디스에이블링된 상태로 획득된 트레이닝 데이터를 가지고 학습하는 구성을 개시하고 있습니다.
좌측의 최초 청구항과 최종 등록청구항에서 추가된 부분이 바로 “노드들의 부분집합이 학습 과정동안 디스에이블링할 확률과 연관되어 있고, 어떠한 노드들을 디스에이블링할지에 대한 결정을 할 때, 해당 확률에 기초해서 결정을 내린다(a subset of the feature detectors being associated with respective probabilities of being disabled during processing of each of the training cases, determining whether to disable each of the feature detectors in the subset based on the respective probability associated with the feature detector)”는 부분입니다.
해당 부분이 심사과정에서 출원인이 추가한 부분이며, 등록을 위해 양보한 부분입니다. 앞서 특허 청구항에 추가된 구성요소는, 특허권자의 권리행사를 제한하는 요소가 된다고 설명드렸습니다.
구글은 특허를 등록받은 이후에도, 제 3자가 “노드들의 일부분들이 디스에이블링될 확률이 설정되어 있고, 이 확률에 따라 각 노드들이 디스에이블링 될지가 영향을 받는다”는 부분까지 활용하는 경우에만, 해당 특허의 권리 침해를 주장할 수 있습니다.
물론 Tensorflow 에서 제공하는 dropout 의 소스코드를 보면, 각 노드들을 디스에이블링할 확률을 설정하고 이에 맞추어 확률론적으로 디스에이블링하는 구조를 포함하고 있습니다. (당소 칼럼: 구글 AI 특허에 대한 이해와 분석 - 텐서플로우란? 참조)
.png)
[자료제공: 주식회사 수아랩 정회희 연구원]
그러나, 자신도 사용하는 기술을 그대로 특허로 등록했다고 해서 아무런 문제가 없는 것은 아닙니다. 물론 라이브러리단에서 노드들의 dropout 확률을 자유롭게 결정하고 뉴럴네트워크의 노드들을 확률적으로 통제하는 것이, dropout 기능을 100% 활용하는 것일 수 있습니다.
그렇다면, 제3자가 dropout 학습 방법에서, 확률론적으로 노드들을 컨트롤하는 것을 포기한다면, dropout 학습 방법이 주는 효과를 모두 활용할 수 없는 것일까요? 만약 특정한 뉴럴 네트워크의 구조가 정해져 있는 상태에서 각각의 노드들을 학습할 미니배치마다 결정론적으로(deterministic)하게 디스에이블링하면 어떻게 될까요?
dropout 학습방법이 과적합(overfitting)을 방지하는 원리 중 하나는, 뉴럴 네트워크에서 각각의 미니배치마다 디스에이블링되는 노드들이 달라지므로, 마치 서로 다른 구조를 갖는 뉴럴 네트워크 들이 각각의 미니배치 단위로 학습된 것 같은 효과를 가진다는 점입니다. 최종적으로 학습된 뉴럴네트워크들에서 추론(inference)이 일어나는 시점에서는 서로 상이한 노드들이 디스에이블된 여러개의 뉴럴 네트워크들이 마치 앙상블된 효과를 내면서, 과적합 문제를 해결할 수 있습니다.
이러한 구조가, 노드들의 디스에이블링 되는 조건을 확률적으로 통제하지 않고, 결정론적으로 통제한다고 해서 달라질 것 같지는 않습니다. 물론 결정론적으로 각 노드들을 통제하는 경우, dropout 기능(“결정론적 dropout”이라고 하겠습니다) 자체가 임의의 뉴럴 네트워크에 적용할 수 있는 범용성이 떨어지거나, 뉴럴 네트워크에서 디스에이블링 되는 노드들이 랜덤화되면서 생기는 이점들을 취하지 못할 수는 있습니다. 그렇다 해도 결정론적 dropout 자체가 일반적인 dropout 의 핵심 메커니즘으로부터 오는 이점을 전혀 얻지 못한다고 보기는 어렵습니다.
즉 다시 말해서, 일반적인 dropout이 100의 효과를 얻을 수 있다면, 결정론적 dropout은 70이나 50, 아니면 30의 효과를 얻는다고 가정할 수도 있습니다.
특허권은 경쟁이 있을때 그 효과를 발휘합니다. 경쟁자가 내가 개발한 기술을 일정기간 동안 활용하지 못하게 하면서 경쟁우위를 점하는 것이 특허가 가지는 1차적인 효용입니다. 그런데, 경쟁자가 내가 가진 기술을 100% 활용하지 않더라도, 내 기술의 일부를 취하고 70%의 효과를 발휘하는 제품을 만들면서, 내 제품보다 50% 가격을 가지는 제품을 출시한다면 어떻게 될까요?
특허권자는 자신이 개발한 기술의 일부를 활용하는 제3자와 싸우면서, 다시 가격 경쟁을 해야하는 처지에 놓이게 됩니다. 이로 인해 특허권자는 온전한 독점권 그리고 그로인한 시장지배력을 누리기 어렵습니다.
2013년 특허에서 구글은 최종적으로 미국특허청에게 등록 허가를 받은 특허의 권리범위가 그다지 맘에 들지 않았을 수 있습니다. 그러나 특허 등록에는 중간이 없습니다. 일단 자기가 양보해서 등록 허락을 받은 특허 권리범위를 수용하고 특허를 등록받거나, 아니면 특허 등록 자체를 포기해야 합니다.
더군다나, 한번 특허가 등록되면, 확정된 권리범위를 추후에 변경하는 것은 불가능에 가깝습니다.

이런 상황에서 구글이 취할 수 있는 선택은 무엇이 있을까요?
계속출원(Continuation Application): 재도전의 기회를...

이러한 상황에서 특허권자가 취할 수 옵션 중 하나는 일단 등록 허가를 받은 특허를 등록하고, 새로운 가지치기 특허를 출원해서 자신이 원하는 더 넓은 권리범위확보를 꾀하는 것입니다. 나라마다 다양한 제도가 있지만, 미국특허법은 계속출원(Continuation Application)이라는 제도를 제공하고 있으며(분할출원(Divisional Application), 부분계속출원(Continuation in-part Application) 등의 제도 또한 존재합니다), 구글은 계속출원 제도를 이용해서 자신들이 애초에 의도했던 더 넓은(특허 청구항에 구성요소들이 되도록 적게 포함된) 특허 권리범위를 확보하기 위해서, 2016, 2019 및 2021년에 반복해서 계속출원을 진행하고 있는 중입니다.
2013년 특허의 등록을 완료하고(일단 미국특허청의 판단을 수용하고), 2016년에 출원한 계속출원의 최종 특허 청구항은 다음과 같습니다. (이해를 위해, 2013년도 특허와 유사한 기술 내용들은 동일한 색상으로 표기하였습니다)

2013년 특허와 비교했을때, 2016년 특허의 특징은 1) 여러개의 미니 배치마다 서로 다른 노드들이 디스에이블링되는 것을 표현하기 위해, 제 1 트레이닝 케이스, 제 2 트레이닝 케이스에 따라 상이한 노드들이 디스에이블링 되는 것을 표현하였습니다(processing the second training case with at least one of the feature detectors in the first set of feature detectors enabled and the second, different set of feature detectors disabled to generate a predicted output for the second training case,).
2) 두번째 특징으로는 이러한 dropout의 특징으로 인해서 학습과정에서 노드들의 동조화(co-adaptation) 및 과적합(overfitting)이 줄어든다(thereby reducing overfitting and reducing co-adaptation of feature detectors by reducing reliance on the first set of one or more feature detectors by other feature detectors in the neural network)는 내용이 특허 청구항에 직접적으로 언급되어 있다는 점 입니다.
특허청구항을 작성하는데 있어서 주로 쓰이는 기술적입 방법이 하나 있습니다. N개의 엔티티들이 서로 상이한 특성을 가지거나 동작을 수행하고 있을때, N개 중에 제 1 엔티티, 그리고 제 2 엔티티가 존재하고, 제 1 엔티티와 제 2 엔티티는 서로 상이한 특성을 가지거나 혹은 동작을 수행한다고 표현하는 것입니다.
이 경우, N개의 엔티티들이 모두 각각 상이한 특성을 가지거나 동작을 수행하는 것 또한, 해당 청구항이 커버할 수 있으며, N개 중에 일부 엔티티들이 동일한 특성을 가지거나 동작을 수행하더라도 마찬가지로 커버할 수 있습니다.
2016년 특허 또한 이를 이용해서, “dropout 과정에서 미니배치마다 상이한 노드들이 디스에이블되는 것”을 “임의의 제 1 및 제 2 트레이닝 케이스가 존재하는데 두 개의 트레이닝 케이스에서 서로 상이한 노드들이 디스에이블링 되는 것”으로 표현하고 있습니다.
2016년 특허에서 특기할만한 점은, dropout 학습 방법의 효과인 동조화 및 과적합 현상의 감소가 특허청구항에 포함되어 있다는 점 입니다.
일반적으로 어떠한 기술의 효과를 청구항에 포함시키는 것은 그다지 바람직한 것은 아닙니다. 실제 특허 등록여부를 심사할때 중요하게 보는 것은, 그 기술의 구성요소이지 효과가 아니어서 특허 등록에 도움이 되지 않고, 오히려 추후에 특허의 권리범위를 제한하는 요소로 동작할 수 있기 때문입니다.
구글은 2016년 특허역시 이 상태로 등록 받고, 발명의 효과를 포함시킨 부분이 맘에 들지 않았는지 2019년에 다시 계속 출원을 진행하게 됩니다.

2019년 계속 출원 특허에서, 구글은 발명의 효과인 학습과정에서 노드들의 동조화(co-adaptation) 및 과적합(overfitting)이 줄어든다(thereby reducing overfitting and reducing co-adaptation of feature detectors by reducing reliance on the first set of one or more feature detectors by other feature detectors in the neural network)는 내용을 삭제하는데 성공합니다.
다만 대신에, 제 1 미니 배치(training case) 및 제 2 미니 배치로 중복하여 트레이닝 과정을 서술하는 구성은 2016년 특허와 동일하게 유지되었으며,
제 1 미니배치(training case)가 끝나고 나서, 제 2 미니배치가 시작되기 전에 제 1 트레이닝 때 디스에이블링된 노드들을 모두 인에이블링한다(enabling the first set of one or more feature detectors after processing the first training case using the neural network and prior to processing a second training case of the plurality of training cases using the neural network)는 구성을 추가하였습니다.
언뜻 보기에 크게 문제는 없어보이는데도 불구하고, 구글은 2021년에 또 다시 새로운 계속출원을 진행하였으며, 현재 해당 청구항은 심사중입니다.

2021년에 출원된 특허는 아직 등록결정이 나지 않았기 때문에, 현재 청구항은 구글이 2021년에 계속 출원을 진행하면서 청구한 최초 청구항에 해당합니다.
2021년 특허의 최초 청구항을 보면, 2013년에 청구항 최초의 본출원의 청구항과 구성요소가 거의 동일합니다.
높은 확률로, 해당 특허 청구항이 아무런 수정없이 등록 되기는 어렵습니다. 특히 2021년 계속출원의 특허를 그대로 등록시켜버린다면, 미국특허청이 2013년 특허에 대해서 내렸던 결정을 스스로 부정하는 모양새가 되기 때문에 더더욱 그러합니다.
반복되는 계속 출원의 이유: 단일 기술에 대한 특허포트폴리오 전략
그렇다면 구글은 왜 만족하지 못하고 지속적인 계속 출원을 반복하는 것 일까요?
구글 특허팀 내부의 사정을 단언할 수 없지만, 이는 중요한 단일 기술에 대한 특허포트폴리오 확보 전략을 진행하는 중일 수도 있습니다.
예를 들어 2013년도 특허 등록 과정에서 최초 청구항에 의해 표현되는 최초 확보하고자 했던 청구범위와, 최종적으로 등록된 청구항에 의해 표현되는 실제 허락받은 청구범위를 다음과 같이 표현할 수 있습니다.

보시는 바와 같이, 실제 허락 받은 청구범위는 최초 확보하고자 했던 청구범위의 일부에 불과합니다. 이 경우, 최초 확보하고자 했던 청구범위와 실제 허락받은 청구범위의 간격을 파고드는 경쟁자들을 효과적으로 제지할 수 없습니다.
그러나 구글이 계속출원을 반복하면서 2016년, 2019년 특허를 확보함으로써, 구글은 dropout 특허에 대한 다양한 방면의 보호범위를 가지는 다양한 특허를 확보하고, 이를 통해 최초 등록받고자 했던 보호범위와 확보된 특허의 권리범위 사이의 간극을 메울 수 있습니다.

2021년 특허 또한, 비록 최초 의도로 했던 권리범위 전체를 커버하지 못한다 하더라도, 실제로 다른 간격을 메울 수 있는 특허를 확보함으로써, 추가적으로 dropout 기술에 대한 더욱 충실한 특허 보호범위를 확보할 수도 있습니다.

경쟁이 격화되고, 제품과 기술이 세분화됨에 따라, 하나의 기술이나 하나의 제품이 단일한 특허에 의해 보호받을 수 있는 가능성은 점점 사라지고 있습니다.
앞서 살펴본 사례처럼, 가출원제도 및 계속출원제도와 같은 다양한 제도를 활용함으로써, 중요한 제품 혹은 기술에 대한 실질적인 보호를 할 수 있는 다양한 전략들이 존재하고 있으며, 해외의 기업들(특히 미국 기업들)은 이를 적극 활용하고 있습니다.
한국 특허법 상 유사제도: 임시출원제도 및 분할출원 제도
한국 특허법에도 이와 유사한 제도들이 존재합니다. 임시출원제도는 미국의 가출원제도를 모델로 도입된 제도로서 출원인들이 형식에 구애받지 않고 최대한 빠른 출원일자를 확보할 수 있도록 도입된 제도입니다.
미국처럼 계속출원, 일부계속출원, 분할출원으로 세분화되어 있지는 않지만, 한국 특허법의 분할 출원 제도 역시 동일한 내용을 공유하는 특허 출원에 대해서 새롭게 출원을 진행할 수 있는 제도입니다.
법개정으로 인하여 한국의 분할출원제도 또한 등록결정을 받은 이후에도 출원이 가능해졌으며, 계속출원과 유사하게 활용할 수 있습니다.
그러나, 해외 기업들에 비해서 우리나라 기업들은 미국에서의 계속출원이나, 한국에서의 분할출원 활용에 대해 익숙하지 않은 편입니다. 저희의 내부적인 통계에 따르면, MS, 오라클, IBM과 같은 미국의 주요 특허 출원인들과 비교해서, 삼성전자의 계속출원 활용비율이 크게 떨어지는 것으로 파악하고 있습니다.

효과적인 특허 전략을 수립하기 위해서는 일정 수준의 이상의 특허를 확보하기 위한 정량적인 투자도 필요하지만, 제도를 효율적으로 활용할 수 있는 전략도 필요합니다. 국내의 많은 출원인들도 전략적인 제도의 활용에 관심을 가질 수 있으면 좋겠습니다.

![구글 AI 특허에 대한 이해와 분석 - 공개 특허 비행사 서약의 긍정적인 효과 [3]](https://ipms-content.piip.co.kr/article-images/1606284935544/99113795-b1c5-466f-975b-ab0759b489a7/01.jpg)
![심사관과 심층적인 인터뷰: Batch Normalization 특허 관련 진행 상황 [1]](https://ipms-content.piip.co.kr/article-images/1599442357749/f4441158-ab34-4fab-8b23-6d3f8538fba5/what would google do.jpg)