
본 포스팅은 주식회사 수아랩의 정회희 연구원의 도움을 받아 작성되었습니다.
사용된 특허에 대한 정보는 인공지능 기반 특허 분석 데이터베이스인 키워트를 사용하여 검색하였습니다.
첫 포스팅에서 살펴본 특허 중 등록된 특허 중 아래의 특허를 예로 들어 살펴보도록 하겠습니다.
System and method for addressing overfitting in a neural network
해당 특허는 drop-out 과 관련된 특허로서 2013년 8월 30일에 최초로 출원되었습니다. 심사를 거쳐 2016년 8월 2일에 최종적으로 등록된 특허입니다.
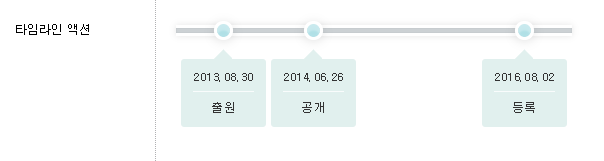
오버피팅을 막기위해 트레이닝 과정에서 노드들(feature detectors)을 디스에이블링 한다는 drop out의 기본적인 기능을 설명하고 있고, 미국 특허청으로부터 1 번의 거절이유통지를 받고 약간의 수정끝에 등록되었습니다.
일반적으로 특허를 받기위해 특허명세서를 작성하고 특허를 신청하게 되면, 특허청이 특허를 등록해줄지 여부에 대한 심사를 진행합니다. 일반적으로 적어도 1번 정도는 특허청으로부터 특허를 내줄 수 없다는 심사 결과를 받게 됩니다. 한국의 기준으로 보면 통계상 90%의 사건들은 적어도 한 번은 특허를 내줄 수 없다는 통지서를 받게 됩니다.
물론 이러한 통지가 최종처분은 아닙니다. 특허를 신청한 사람은 자신의 의견을 개진할 기회를 갖게 되는데, 보통 이 의견 개진 과정에서 특허를 받고자 하는 권리범위를 조금씩 축소하는 절차를 거치기도 합니다. 특허청과 사이에서 의견을 조율하는 절차라고 볼 수 있겠습니다.
최종적으로 구글이 등록받은 특허의 권리범위는 다음과 같습니다.
“1. A computer-implemented method comprising:
obtaining a plurality of training cases; and training a neural network having a plurality of layers on the plurality of training cases, each of the layers including one or more feature detectors, each of the feature detectors having a corresponding set of weights, and a subset of the feature detectors being associated with respective probabilities of being disabled during processing of each of the training cases, wherein training the neural network on the plurality of training cases comprises, for each of the training cases respectively:
determining one or more feature detectors to disable during processing of the training case, comprising determining whether to disable each of the feature detectors in the subset based on the respective probability associated with the feature detector, disabling the one or more feature detectors in accordance with the determining, and processing the training case using the neural network with the one or more feature detectors disabled to generate a predicted output for the training case.”
특허의 권리는 특허 청구항에서 설정된 범위에 한정됩니다. 특허 청구항에 포함되는 모든 구성요소를 다 실시하는 경우 해당 특허를 침해하는 것으로 판단될 수 있습니다.
두 번째 칼럼에서, Tensorflow 가 채택한 Apache 2.0 License 에 따르면, 해당 라이선스는 해당 오픈소스 소프트웨어를 사용하게 되면 침해할 수 밖에 없는 특허에 대한 사용권을 허여한다고 정리한 바 있습니다.
즉, 해당 특허가 Tensorflow를 사용하는데 있어서 침해할 수 밖에 없는 특허이면, 오히려 사용자들이 걱정할 필요가 없는 특허입니다. Apache 2.0 라이선스에 의해 해당 특허에 대한 사용권을 자동으로 획득하기 때문입니다. 어찌보면 조금 아이러니한 상황이네요.
청구항의 각 구성요소들을 보시겠습니다.
뉴럴 네트워크의 트레이닝 과정에서 라벨링된 데이터를 획득하는 것(obtaining a plurality of training cases)은 당연합니다. 그리고 뉴럴 네트워크, 특히 딥뉴럴 네트워크는 다층의 레이어들을 가지고 있으며(training a neural network having a plurality of layers on the plurality of training cases) 각 레이어들은 가중치 정보를 가지고 있는 다수의 노드들 (each of the layers including one or more feature detectors, each of the feature detectors having a corresponding set of weights)을 가지고 있습니다.
따라서, 청구항에서 붉은색으로 표시된 부분은 Tensorflow를 쓰는 경우 당연히 사용하게 되는 부분이라 볼 수 있겠습니다.
다음으로, Tensorflow 에서 dropout library에 대해서 설명하고 있는 링크를 보시겠습니다.
해당 링크를 보시면, “Dropout은 트레이닝 중 각 업데이트에서 랜덤하게 일정 비율의 입력 유닛을 0으로 설정한다”고 설명하고 있습니다. 따라서 입력을 0으로 설정할 노드를 결정하고(determining one or more feature detectors to disable during processing of the training case), 해당 노드를 디스에이블링하고(disabling the one or more feature detectors in accordance with the determining), 그 상태로 트레이닝을 수행함(processing the training case using the neural network with the one or more feature detectors disabled to generate a predicted output for the training case)을 알 수 있습니다.
이제 관건은, Tensorflow가 dropout을 수행함에 있어서, 각 노드가 disable 될 확률을 설정하고(a subset of the feature detectors being associated with respective probabilities of being disabled during processing of each of the training cases), 이 확률에 기초하여 디스에이블할(입력을 0으로 만들) 노드의 비율을 결정하는지(determining whether to disable each of the feature detectors in the subset based on the respective probability associated with the feature detector)여부를 판단해야할 차례입니다.
dropout 의 소스코드를 살펴보도록 하겠습니다.
.png)
[자료제공: 주식회사 수아랩 정회희 연구원]
해당 코드를 살펴보면, 전체 노드 중 얼마만큼의 노드를 남길지 즉, 각 노드 중 disable 될 노드의 비율을 정하는 keep_prob 변수(0부터 1사이의 값)를 이용하여 노드를 dropout을 구현하는 구성을 보여주고 있습니다.
라인 2102-2103에서 0-1 까지의 uniform distribution을 취하는 랜덤 값을 생성하여 이를 keep_prob 변수와 더하게 됩니다.
이렇게 되면 keep_prob 값의 크기에 해당하는 비율만큼 1보다 큰 random 값이 생성되고, 나머지 random 값들은 1보다 작게됩니다.
소스코드의 라인 2106-2108은 이렇게 생성된 랜덤 변수들을 이용하여 1보다 크면 1을, 1보다 작으면 0을 할당하여 각노드값에 곱하는 것을 보여줍니다.
이렇게 하면 각 노드의 입력값이 keep_prob 의 값에 해당하는 비율만큼 그 값을 유지하고, 나머지 노드들은 drop out 되는 효과를 얻게 됩니다.
즉, 이로 인해서, 각 노드가 disable 될 확률을 설정하고(a subset of the feature detectors being associated with respective probabilities of being disabled during processing of each of the training cases), 이 확률에 기초하여 디스에이블할(입력을 0으로 만들) 노드의 비율을 결정(determining whether to disable each of the feature detectors in the subset based on the respective probability associated with the feature detector)하는 것이 명백해졌습니다.
이로인해, 해당 청구항의 모든 구성요소들은 Tensorflow의 dropout 기능에서 제공하는 필수 요소들임이 밝혀졌습니다. 따라서, 해당 청구항은 Tesnsorflow의 라이선스에 의거해서 사용자가 걱정할 필요가 없는 청구항에 해당합니다.
실제 전체 청구항에 대한 권리범위 판단은 이것보다 더 복잡할 수 있습니다. 하나의 특허에는 여러개의 청구항이 있기 때문입니다. 당연히 모든 청구항에 대해서 이렇게 Apache 2.0 라이선스에 따른 사용권 존재 여부를 판단하는 것은 매우 시간과 비용이 많이 드는 일 입니다.
구글의 의도는 무엇일까요, 일단 Tensorflow의 핵심기능을 구성하는 코어 특허들이 Tensorflow 사용자들을 겨냥하고 있지 않다는 것은 쉽게 추측해볼 수 있습니다. 아직 구글은 OPN(Open Patent Non assertion Pledge)을 통해서 딥러닝 특허들을 이용가능한 것으로 선언한 바는 없습니다. 그러나 이는 구글 내부의 관리상의 문제이거나, 구글이 딥러닝 특허 목록을 정리한 후 리스트를 업데이트 하려 했을지도 모릅니다. 어쩌면 이 포스팅을 보고 몇몇 딥러닝 특허들을 OPN에 선언할지도 모르겠습니다.
그러나 오픈소스 라이선스만을 믿고 구글의 딥러닝 특허들은 모두 걱정할 필요가 없다고 생각하는 것은 위험합니다. 구글의 특허들은 Tensorflow에서 제공하는 기본 기능에 해당하는 특허들만 있는 것이 아닙니다. 실제 제품 구현단에서 적용할 수 있는 특허들도 다수 보유하고 있습니다.
Tensorflow를 사용하여 연구되고 개발된 애플리케이션이 구글의 핵심 딥러닝 특허는 침해하지 않더라도, 구글이 보유하고 있는 구체적인 세부 서비스 특허와 매칭되어 공격을 받을 수 있는 가능성도 존재합니다.
일반적인 인식과는 달리, 딥러닝과 인공지능 관련 기술에 있어서도 여전히 특허는 무시할 수 없는 존재 임이 명백합니다. 구글의 선한 의도를 믿더라도, 구글 못지않게 무시무시한 특허를 가지고 있는 다른 기업들도 많습니다.
앞으로 특허 관점에서 바라본 인공지능에 대한 이야기들을 가능한 쉽게 소개해보고자 합니다.
감사합니다.

![구글 AI 특허에 대한 이해와 분석 - 오픈 소스 소프트웨어 라이선스와 특허 [2]](https://ipms-content.piip.co.kr/article-images/1606284805998/0d8ba102-de46-45b3-8b64-49a458b26549/google open source software patent.jpg)
![구글 AI 특허에 대한 이해와 분석 - 구글과의 위험한 거래 [1]](https://ipms-content.piip.co.kr/article-images/1606285024096/a70240cf-5da0-4db1-950b-d0d51068cb04/deal with the devil.jpg)